Ao trabalhar com dados no Pandas, realizamos uma vasta gama de operações nos dados para obter os dados no formato desejado. Uma dessas operações pode ser a necessidade de criar novas colunas no DataFrame com base nas colunas existentes no DataFrame.
Como exemplo, vou criar uma tabela com dados de algumas pessoas. A tabela será composta por duas colunas: nome e idade.
Com a tabela desenvolvida, vou classificar a pessoa como adulto ou menor de idade através da idade.
Neste caso, vamos criar uma nova coluna com base em uma coluna já existente:
#Importando a biblioteca pandas
import pandas as pd
# Criando a tabela de dados
tabela = {'Nome do usuário': ['Araújo', 'Moisés', 'Catumbela', 'Victor',
'Sambimbia', 'Margarida', 'Manuel', 'Mendrote'],
'Idade': [15, 23, 25, 9, 67, 54, 42, 65]}
df = pd.DataFrame(tabela, columns = ['Nome do usuário', 'Idade'])
faixa_idade = []
# Para cada linha da coluna, vamos pegar a faixa de idade
for idade in df['Idade']:
if idade >= 18: # se pessoa é adulta
faixa_idade.append('Adulto')
elif idade < 18: # se pessoa é menor de idade
faixa_idade.append("Menor de idade")
else:
faixa_idade.append("S/C")
# Criando uma nova coluna que vai receber as faixas de idade
df['Status'] = faixa_idade
print(df)
Executando as linhas de código, teremos o seguinte: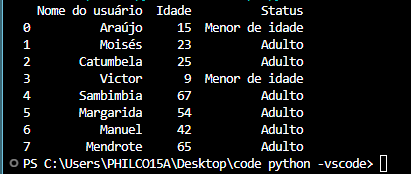
Comentários
Postar um comentário